TP 5 : Planification dans les jeux competitifs
Introduction
Dans ce projet, vous allez concevoir des agents pour la version classique de Pacman, incluant les fantômes. Vous implémenterez notamment minimax et expectimax, et vous vous essaierez à la conception de fonction d'évaluation.
Le code du projet est similaire aux TP que vous avez déjà fait.
Le code pour ce projet contient les fichiers ci-dessous, disponibles dans un fichier compressé.
| Les fichiers que vous allez éditer : | |
multiAgents.py |
Où tout le code de vos agents ira. |
| Des fichiers que vous pouvez lire mais PAS éditer : | |
pacman.py |
Fichier principal qui lance les parties de Pacman. Ce fichier défini également un type Pacman
GameState, que vous utiliserez dans ce projet.
|
game.py |
Contient la logique du monde de Pacman. Ce fichier défini plusieurs type importants comme AgentState,
Agent, Direction et Grid.
|
util.py |
Contient des structures de données utiles pour l'implémentation des algorithmes de recherche. Vous n'avez pas à utiliser ces structures pour ce projet mais vous pourriez trouver d'autres fonctions implémentées ici utiles. |
| Vous pouvez ignorer les autres fichiers qui servent de support. | |
Fichiers à modifier et soumettre : vous devez remplir les sections manquantes du fichier
multiAgents.py. Veuillez ne pas modifier les autres fichiers.
Évaluation : l'auto-correcteur s'assure du bon fonctionnement de votre code. Ne changez aucun nom de fonction ou nom de classe dans le code, sans quoi l'auto-correcteur ne fonctionnera pas. L'auto-correcteur ne détermine pas entièrement votre résultat final. La qualité de votre implémentation - et non les résultats obtenus par l'auto-correcteur - déterminent votre résultat final.
Aide : N'hésitez pas à contacter les assistants à l'enseignement pour ce cours afin de vous aider dans le travail.
Plagiat :
Nous prendrons soin de vérifier votre code par rapport aux autres soumissions de la classe afin de
détecter toute redondance logique.
Tout cas de plagiat sera sanctionné adéquatement. Voir le document
informatif du Groupe de travail antiplagiat de l'Université de Sherbrooke à cet effet.
Vous utiliserez l'autogradeur avec les commandes suivantes pour évaluer vos solutions :
python autograder.pyIl peut être exécuté pour une question particulière, telle que la q2, par :
python autograder.py -q q2Il peut être exécuté pour un test particulier par des commandes de la forme :
python autograder.py -t test_cases/q2/0-small-treeBienvenue dans Pacman multi-agents
Pour commencer, lancez Pacman en mode de contrôle manuel, qui utilise les touches de direction :
python pacman.pyMaintenant, lancez la classe ReflexAgent fourni dans multiAgents.py.
python pacman.py -p ReflexAgentNotez qu'il joue plutot mal même sur des niveaux simples :
python pacman.py -p ReflexAgent -l testClassicInspectez son code (dans multiAgents.py) et assurez-vous de comprendre ce qu'il fait.
Question 1 : Reflex Agent
Améliorez le ReflexAgent dans multiAgents.py afin qu'il joue correctement.
Le code donné pour l'agent à réflexes fourni des exemples utiles de méthodes qui interrogent le GameState
pour des informations. Un bon agent à réflexes devra considérer les positions de la nourriture et des
fantômes pour obtenir de
bonnes performances. Votre agent devrait facilement et regulièrement réussir le niveau
testClassic :
python pacman.py -p ReflexAgent -l testClassicEssayez votre agent sur le niveau par défaut mediumClassic avec un ou deux fantômes (et
l'animation desactivée pour accélérer l'affichage) :
python pacman.py --frameTime 0 -p ReflexAgent -k 1python pacman.py --frameTime 0 -p ReflexAgent -k 2Comment s'en sort votre agent ? Il mourra probablement avec 2 fantômes sur le niveau par défaut, à moins que votre function d'évaluation ne soit vraiment bonne.
Note : Rappelez-vous que newFood a la methode asList().
Note : Comme features, essayez l'inverse de valeurs importantes (comme la distance à la nourriture) plutôt que les valeurs en elles-meme.
Note : La fonction d'évaluation que vous écrivez évalue des paires état-action; ce ne sera pas toujours le cas.
Note : Vous pourriez trouver utile, pour debugger, de voir le contenu des objets. Pour cela vous
pouvez afficher la représentation en chaîne de caractères de l'objet.
Par exemple, print(newGhostStates).
Options : Les fantômes par défaut sont aléatoires; vous pouvez vous amuser à les rendre plus
intelligents avec des fantômes directionnels en utilisant -g DirectionalGhost.
Si l'aléatoire vous empêche de voir si votre agent s'améliore, vous pouvez utiliser -f pour
utiliser une seed fixe (rendant les choix aléatoires identiques d'une partie à l'autre).
Vous pouvez jouer plusieurs parties à la suite avec -n. Désactivez les graphismes avec
--no-graphic pour jouer de nombreuses parties rapidement.
Notation : Votre agent sera évalué sur le niveau openClassic 10 fois. Vous pouvez
essayer votre agent sous ces conditions avec :
python autograder.py --q q1Ne passez pas trop de temps sur cette question, le principal du TP se situe dans les autres questions.
Barème
| Critère | Points |
| Au moins 5 victoires | 1 |
| 10 victoires | 1 |
| Moyenne du score > 500 | 1 |
| Moyenne du score > 1000 | 1 |
| Qualité / lisibilité du code | 1 |
| Total | 5 |
Question 2 : Minimax
Maintenant vous allez concevoir un agent de recherche compétitif dans la classe
MinimaxAgent dans multiAgents.py.
Votre agent Minimax doit fonctionner avec un nombre quelconque de fantômes, donc vous devez écrire un
algorithme qui soit un peu plus générique que
celui vu en cours. En particulier, votre arbre minimax aura plusieurs couches min (une pour chaque
fantôme) pour chaque couche max.
Votre code doit aussi explorer l'arbre à une profondeur arbitraire. Vous évaluerez les feuilles de votre
arbre minimax en utilisant la fonction self.evaluationFunction,
qui par défaut appelle scoreévaluationFunction. MinimaxAgent hérite de MultiAgentSearchAgent,
qui donne accès à
self.evaluationFunction.
Assurez-vous que votre code fasse référence à ces deux variables lorsque nécessaire, car ces variables
contiendront les valeurs passées par les options de ligne de commande.
Cela correspond au point 2) de la slide 16 de "ift615-17-Planification dans les jeux compétitifs".
Important : un niveau de profondeur de recherche correspond à un mouvement de Pacman ET les mouvements des fantômes. Donc une recherche de profondeur 2 implique un mouvement de Pacman puis de tous les fantômes, deux fois.
Notation : Pour évaluer votre code l'autocorrecteur vérifiera que vous explorez le bon nombre
d'états. C'est la seule manière fiable de détecter des erreurs subtiles dans des implémentations de
minimax.
De ce fait, l'autocorrecteur sera très strict sur le nombre de fois que vous appelez GameState.generateSuccessor.
Si vous l'appelez plus ou moins de fois que nécessaire, l'autocorrecteur le signalera.
Pour tester votre code, utilisez :
python autograder.py --q q2Cela montrera comment votre code marche sur un nombre de petits arbres ainsi qu'une partie de Pacman. Pour l'éxecuter sans affichage :
python autograder.py --q q2 --no-graphicsIndices et observations
- Indice : implémentez votre algorithme recursivement.
- Une implémentation correcte de minimax fera perdre Pacman dans certaines parties. Ce n'est pas un problème étant donné que c'est attendu, les tests seront validés.
-
La fonction d'évaluation pour la partie de Pacman pour cette question est déjà écrite (
self.evaluationFunction). Vous ne devriez pas changer cette fonction mais remarquez que maintenant nous évaluons des états plutot que des actions contrairement à l'agent à réflexes. Les agents look-ahead évaluent les états futurs alors que les agents à réflexes évaluent les actions depuis l'état actuel. -
Les valeurs minimax depuis l'état initial dans le niveau
minimaxClassicsont 9, 8, 7 et -492 pour les profondeurs de recherche 1, 2, 3 et 4 respectivement. Notez que votre agent minimax gagnera souvent (665/1000 dans notre cas) malgrès la prédiction pessimiste de minimax avec une profondeur de recherche de 4.
Copypython pacman.py -p MinimaxAgent -l minimaxClassic -a depth=4 - Pacman est toujours l'agent 0, et les agents bougent dans l'ordre croissant des indices (donc Pacman bouge toujours en premier).
-
Tous les états dans minimax sont des
GameStates, soit donnés àgetActionsoit générés parGameState.generateSuccessor. Dans ce projet, vous ne simplifierez pas les états. -
Sur des niveaux plus grands comme
openClassicetmediumClassic, vous remarquerez que Pacman est bon à ne pas mourir mais n'arrive pas à gagner. Il se deplacera sans vraiment faire de progrès. Il peut même se déplacer autour d'un point de nourriture sans le manger simplement parce qu'il ne sait pas ou il irait après. Ne vous inquiétez pas si remarquez ce comportement, la question 5 résoudra ces problèmes. -
Quand Pacman pense sa mort inévitable, il essaiera souvent de finir la partie le plus vite possible
à cause de la pénalité constante (à chaque tour le score de Pacman reçoit -1). Parfois, c'est la
mauvaise chose à faire avec des fantômes aléatoires,
mais minimax suppose toujours le pire :
Assurez vous de comprendre pourquoi Pacman se rue sur le fantôme le plus près dans ce cas.
Copypython pacman.py -p MinimaxAgent -l trappedClassic -a depth=3
Barème
| Critère | Points |
| Réussite de tous les tests | 5 |
| Qualité / lisibilité du code | 1 |
| Total | 6 |
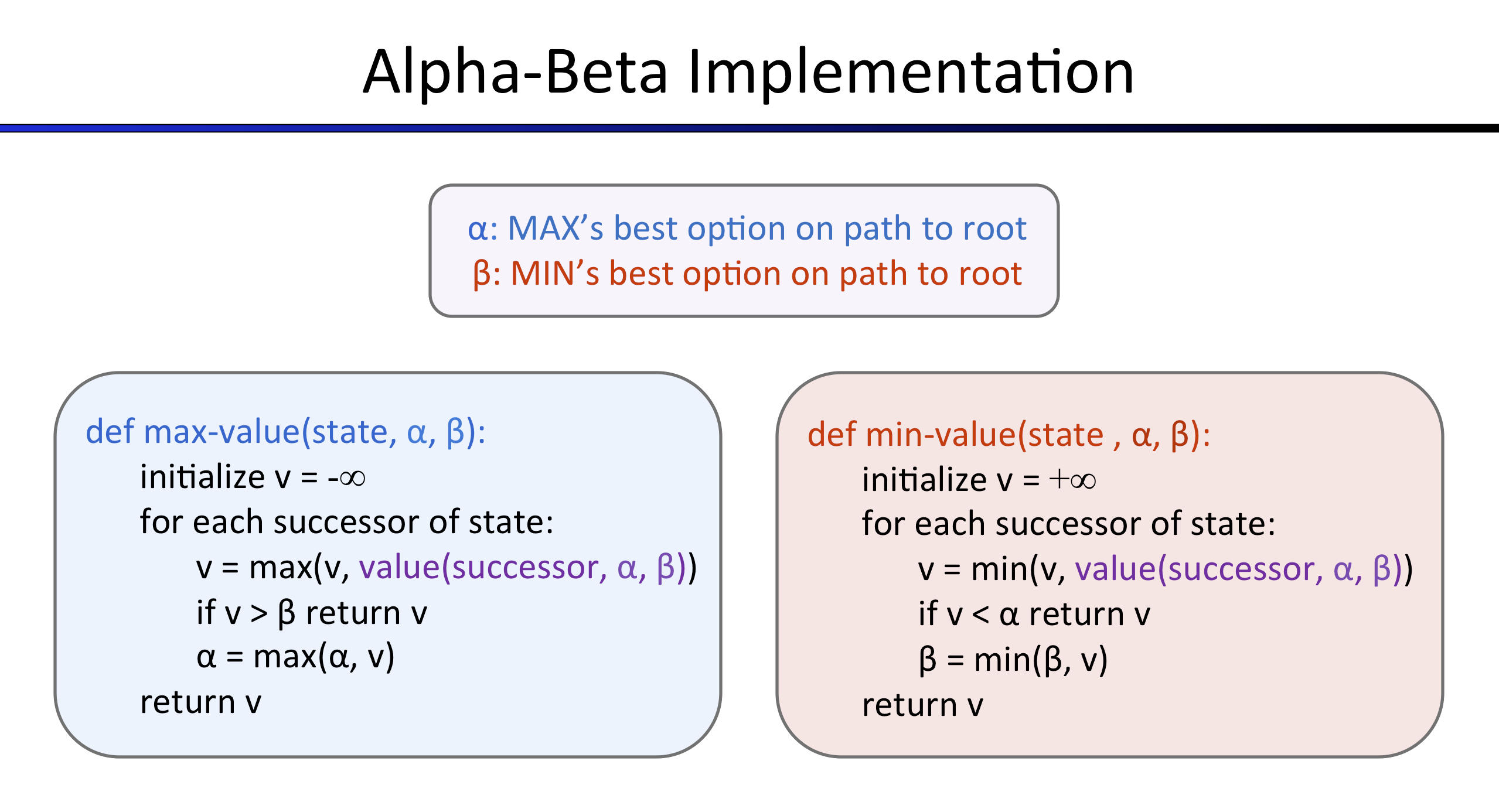
Question 3 : Élagage Alpha-Beta
Faites un nouvel agent qui utilise l'élagage alpha-beta pour explorer l'arbre minimax plus efficacement,
dans AlphaBetaAgent.
Ici encore, votre algorithme doit être plus général que le pseudocode vu en cours, donc une partie de la
difficultée est d'étendre l'élagage alpha-beta à plusieurs
agents min.
Vous devriez noter un gain de temps (peut être qu'alpha-beta avec profondeur 3 ira aussi vite que
minimax avec profondeur 2). Idéalement, avec une profondeur 3 sur le niveau
smallClassic, votre algorithme devrait prendre quelques secondes ou moins par coup.
python pacman.py -p AlphaBetaAgent -l smallClassic -a depth=3
Les valeurs minimax pour l'agent AlphaBetaAgent doivent être les mêmes que pour l'agent
MinimaxAgent, cependant les actions choisies peuvent varier dû une stratégie différente en
cas d'égalité (des valeurs). Les valeurs minimax
pour le niveau minimaxClassic sont de 9, 8, 7 et -492 pour les profondeurs 1, 2, 3 et 4
respectivement.
Notation : Parce que l'autocorrecteur vérifie votre code pour déterminer si vous explorez le bon
nombre d'états, il est important que vous ne changiez pas l'ordre des enfants dans l'arbre.
En d'autres termes, les états successeurs doivent être traités dans l'ordre dans lequel ils sont
retournés par GameState.getLegalActions. Enfin, n'appelez pas GameState.generateSuccessor
plus que nécessaire.
Vous ne devez pas couper les branches en cas d'égalité pour correspondre aux états explorés par l'autocorrecteur.
Le pseudocode ci-dessous représente l'algorithme que vous devez implémenter pour cette question.
Pour tester votre code, utilisez :
python autograder.py -q q3Une implémentation correcte de l'élagage alpha-beta n'empêchera pas Pacman de perdre dans certains des tests. Ce n'est pas un problème puisqu'il s'agit du comportement attendu.
Barème
| Critère | Points |
| Code fonctionnel | 5 |
| Qualité / lisibilité du code | 1 |
| Total | 6 |
Question 4 : Expectimax
Minimax et alpha-beta sont très bons, mais les deux supposent que vous jouez contre un adversaire qui
fait des choix optimaux. Comme toute personne qui a déjà joué au tic-tac-toe vous le dira,
ce n'est pas toujours le cas. Dans cette question, vous implémenterez ExpectimaxAgent, qui
est utile pour modéliser des comportements probabilistes d'agents qui font des choix suboptimaux.
Comme pour les algorithmes de recherche ou de satisfaction de contraintes, la beauté de ces algorithmes est leur applicabilité générale. Pour accélérer le développement, vous avez accès à des tests basés sur des arbres quelconques. Vous pouvez tester votre implémentation sur des tests et une partie de Pacman avec :
python autograder.py -q q4
Une fois que votre algorithme marche sur des petits arbres, vous pouvez observer ses performances dans
Pacman.
Des fantômes aléatoire ne sont pas des agents minimax optimaux, ainsi les modéliser avec une recherche
minimax n'est pas forcement appropriée. ExpectimaxAgent ne prendra plus le minimum sur
toutes les
actions des fantômes mais l'espérance, en fonction du modèle de fonctionnement des fantômes que votre
agent a. Pour simplifier votre code, supposez que vous n'affronterez que des adversaires qui choisissent
leur action au hasard (uniformément)
parmi leurs actions possibles (getLegalActions).
Pour voir comment ExpectimaxAgent agit dans Pacman, lancez :
python pacman.py -p ExpectimaxAgent -l minimaxClassic -a depth=3Vous devriez observer une approche plus cavalière à proximité des fantômes. En particulier, si Pacman perçoit qu'il est potentiellement coincé mais qu'il peut s'échapper pour attraper de la nourriture, il essaiera. Étudiez les résultats dans les scénarios suivants :
python pacman.py -p AlphaBetaAgent -l trappedClassic -a depth=3 -q -n 10python pacman.py -p ExpectimaxAgent -l trappedClassic -a depth=3 -q -n 10
Vous devriez voir que ExpectimaxAgent gagne environ la moitié du temps, tandis que AlphaBetaAgent
perd constamment.
Une implémentation correcte d'expectimax n'empêchera pas Pacman de perdre dans certains des tests. Ce n'est pas un problème puisqu'il s'agit du comportement attendu.
Barème
| Critère | Points |
| Code fonctionnel | 5 |
| Qualité / lisibilité du code | 1 |
| Total | 6 |
Question 5 : Fonction d'évaluation
Écrivez une meilleure fonction d'évaluation pour Pacman dans betterEvaluationFunction.
La fonction d'évaluation doit évaluer des états, et non des actions comme la fonction d'évaluation de
l'agent à réflexes.
Avec une profondeur de recherche de 2, votre fonction d'évaluation devrait reussir le niveau smallClassic
avec un fantôme aléatoire plus de la moitié du temps.
Votre code doit tourner à une vitesse raisonnable. Pour avoir 100% des points, Pacman doit avoir en
moyenne 1000 points lorsqu'il gagne.
Vous devez mettre une courte (une ou deux phrases suffisent) explication / description de ce que votre fonction d'évaluation fait et des choix que vous avez fait.
Notation : l'autocorrecteur testera votre agent sur le niveau smallClassic 10 fois.
Barème
| Critère | Points |
| Pas d'explications | 0 POUR TOUTE LA QUESTION |
| Au moins une victoire sans timeout | +1 |
| Au moins 5 victoires | +1 |
| 10 victoires | +1 |
| Score moyen d'au moins 500 points | +1 |
| Score moyen d'au moins 1000 points | +1 |
| Si les parties prennent moins de 30s en moyenne ET au moins 5 victoires | +1 |
| Qualité / lisibilité du code | 1 |
| Total | 7 |
Vous pouvez tester votre agent avec :
python autograder.py -q q5Votre code sera testé avec les graphismes desactivés :
python autograder.py -q q5 --no-graphicsLes équipes:
| Membre 1 | Membre 2 |
|---|---|
| Boutin, Karl | Tétreault, Etienne |
| Grenier, Philippe-Olivier | Dia, Adam |
| Desfossés, Alexandre | Gauthier, Carl |
| Ménard Tétreault, Yuhan | ~ |
| Philion, Guillaume | Charbonneau, Victor |
| Lavallée, Louis | Boulanger, Bastien |
| Pépin, Pierre-Luc | Allard, Cloé |
| Breton Corona, Eduardo Yvan | Bergeron, Marc-Olivier |
| Yahya, Mohamed | Tientcheu Tchako, David Jeeson |
| Rouabah, Lokman | Giasson, Frédéric |
| Duchesneau, Paul | Krid, Ahmed Bahaedine |
| Carignan, Benjamin | Turcotte, Raphaël |
| Proulx, Hugo | Lamothe-Morin, Zoé |
| Bourgeois, Thomas | Pion, Raphaël |
| Girard Hivon, Maxime | Lessard, Nathan |
| Mailhot, Christophe | Gendreau, Tommy |
| Crozet, Thomas | Bellavance, Nicolas |