
IFT 615 — Intelligence artificielle
Hiver 2024
TP3
Remise: Jeudi 14 mars à minuit
Fichiers sources
Mode de soumission: Turnin TP3
Total de points 30. Pondération de 8%.
NB: Tout retard vaudra 0.
Équipe:
La composition des équipes est fournie avec cet énoncé et est obligatoire. [cliquez ici pour voir]
Enseignant : Froduald Kabanza, Courriel: froduald.kabanza@usherbrooke.ca
Auxiliaire : D'Jeff Kanda Nkashama, Courriel: djeff.nkashama.kanda@usherbrooke.ca
Source: The Pac-Man Projects, University of California, Berkeley
Évaluation
Votre implementation sera évaluée par un correcteur automatique autograder.py. Veuillez ne pas changer les noms
des fonctions ou des
classes fournies dans le code, sinon vous allez perturber le correcteur automatique.
Veuillez noter que votre note finale peut être différente de la note que vous obtenez avec le correcteur automatique.
Soumission
Vous devez soumettre les fichiers bustersAgents.py, NaiveBayesClassifier, et inference.py, ainsi qu’un document solution.pdf.
Plagiat
Nous prendrons soin de vérifier votre code par rapport aux autres soumissions de la classe afin de détecter toute redondance logique.
Tout cas de plagiat sera sanctionné adéquatement. Voir le document informatif du Groupe de travail antiplagiat de l’Université de Sherbrooke à cet effet.
Introduction
 Dans ce projet, vous allez concevoir des agents Pacman qui utilisent des capteurs pour localiser et
manger des fantômes
invisibles. Vous passerez de la localisation de fantômes uniques et stationnaires à la chasse de meutes
de fantômes
multiples en mouvement.
Dans ce projet, vous allez concevoir des agents Pacman qui utilisent des capteurs pour localiser et
manger des fantômes
invisibles. Vous passerez de la localisation de fantômes uniques et stationnaires à la chasse de meutes
de fantômes
multiples en mouvement.
Le code de ce projet contient plusieurs fichiers, mais vous êtes appelés à ne modifier que les fichiers
bustersAgents.py, inference.py et NaiveBayesClassifier aux endroits bien
indiqués.
def observeUpdate(self, observation, gameState):
"""
Update beliefs based on the distance observation and Pacman's position.
"""
"*** YOUR CODE HERE ***"
Toutefois, vous pouvez consulter le contenu des autres fichiers sans les modifiers.
Dans ce jeu, Pacman est équipé des capteurs qui fournissent des lectures bruitées de la distance de Manhattan à chaque fantôme. Le jeu se termine lorsque Pacman a mangé tous les fantômes. Pour commencer, essayez de jouer vous-même au jeu en utilisant le clavier.
python busters.py
Questions
Tout au long de ce projet, nous utiliserons la classe DiscreteDistribution
définie dans inference.py pour modéliser
les distributions de croyances et de poids. Cette classe est une extension de la classe dictionnaire
Python,
où les clés sont les différents éléments discrets de notre distribution, et les valeurs correspondantes
sont
proportionnelles à la croyance ou au poids que la distribution attribue à cet élément. Il vous est
demandé
de compléter les parties manquantes de cette classe, ce qui sera crucial pour toutes les autres
questions.
Prérequis
Question 0: 1 point
Tout d’abord, implementez la méthode normalize,
qui normalise les valeurs de la distribution pour que leur somme
soit égale à un.
Note
Pour une distribution vide ou une distribution dont toutes les valeurs sont égales à zéro, ne faites rien. Notez que cette méthode modifie directement la distribution, au lieu de renvoyer une nouvelle distribution.
Inférence exacte
Question 1 : 2 points
Dans cette question, vous allez implémenter la fonction
getObservationProb(noisyDistance, pacmanPosition,
ghostPosition, jailPosition)
de la classe de base InferenceModule dans
inference.py.
Cette fonction renvoie la probabilité \(P(noisyDistance\ |\ pacmanPosition,\ ghostPosition)\) de la
lecture bruitée de la distance étant donné la position de Pacman et la position du fantôme.
Vous n'avez pas à calculer directement cette probabilité. Vous pouvez appeler la fonction busters.getObservationProbability(noisyDistance,
trueDistance)
qui renvoie une distribution de probabilité sur les lectures de distance étant donné la vraie distance
entre Pacman et le fantôme, \(P(noisyDistance\ |\ trueDistance)\). La fonction manhattanDistance est déjà implémentée et
permet le calcul de la distance de Manhattan entre Pacman et celui du fantôme.
Lorsqu’un fantôme est capturé, il est envoyé à l’emplacement de la prison, et le capteur de distance renvoie de manière déterministe
None.
Une bonne implémentation devrait gérer les cas particulier suivants:
- Si le fantôme est en prison et si
noisyDistanceest indéfinie simultanément, alors la probabilité est 1. - Au contraire, la probabilité que
noisyDistancesoit indéfinie lorsque le fantôme n'est pas en prison en même temps est nulle. De la même manière, si le fantôme est en prison alorsnoisyDistanceest nécessairement nul aussi. Sinon, on retourne 0.
Vous pouvez tester votre code avec le correcteur automatique en utilisant la commande suivante:
python autograder.py -q q1
Question 2 : 3 points
Dans cette question, vous devez implémenter la méthode observeUpdate(observation, gameState) de la
classe ExactInference de inference.py pour mettre
à jour correctement la distribution des croyances de l’agent sur les positions des fantômes en fonction
d’une observation
des capteurs de Pacman. Les croyances représentent la probabilité que le fantôme se trouve à un endroit
particulier, et
sont stockées sous la forme d’un objet DiscreteDistribution
dans un champ appelé self.beliefs, que vous
devez mettre à jour.
Vous devez itérer vos mises à jour sur la variable self.allPositions
qui inclut toutes les
positions légales du fantôme, plus la position spéciale de la prison.
Pour votre implémentation, pensez à utiliser la fonction self.getObservationProb de la question 1, et les
fonctions
gameState.getPacmanPosition() et self.getJailPosition() pour obtenir
respectivement la position de Pacman et la position de
la prison .
Dans l’affichage de Pacman, les croyances postérieures élevées sont représentées par des couleurs vives, tandis que les croyances faibles sont représentées par des couleurs faibles. Vous devriez commencer avec un grand nuage de croyances qui se réduit au fur et à mesure que les preuves s’accumulent. En observant les cas de test, assurez-vous de comprendre comment les carrés convergent vers leur coloration finale.
python autograder.py -q q2
Si vous souhaitez exécuter ce test (ou tout autre test) sans graphiques, vous pouvez ajouter l’option suivante :
python autograder.py -q q2 --no-graphic
Question 3 : 4 points
Supposons que Pacman ait également des connaissances sur la façon dont un fantôme peut se déplacer. Par exemple, un fantôme ne peut pas traverser un mur et est limité dans ses déplacements en fonction du temps. Ces informations permettraient au Pacman une mise à jour plus fine de son système de croyance.
Dans la question précédente, vous avez implémenté la mise à jour des croyances de Pacman en fonction de
ses observations.
Dans cette question, on augmente ce système de croyances avec des informations complémentaires.
Vous devez implémenter la fonction elapseTime
dans ExactInference. L’étape elapseTime devrait, pour
ce problème, mettre à jour la croyance à chaque position sur la carte après l’écoulement d’un pas de
temps. Votre agent
a accès à la distribution des actions pour le fantôme par le biais de self.getPositionDistribution. Afin d’obtenir
la distribution sur les nouvelles positions du fantôme, étant donné sa position précédente, utilisez
cette ligne de code :
newPosDist = self.getPositionDistribution(gameState, oldPos)
où oldPos se réfère à la position précédente du
fantôme.
Utilisez encore self.allPositions pour obtenir
la liste des positions précédentes.
newPosDist est un objet DiscreteDistribution qui donne une liste
de positions et leur probabilité au temps t+1 en fonction de la position oldPos au temps t.
python autograder.py -q q3
Question 4 : 2 points
Cette question utilisera vos implémentations
observeUpdate et elapseTime
ensemble, ainsi qu’une stratégie de chasse simple que vous implémenterez.
Dans cette stratégie, Pacman suppose que chaque fantôme se trouve dans la position la plus
probable selon ses croyances, puis se dirige vers le fantôme le plus proche.
Attention, vous ne devez pas appeler directement les fonctions
observeUpdate et elapseTime.
Le backend se charge de les appeler à votre place.
Implémentez la méthode chooseAction de GreedyBustersAgent dans bustersAgents.py (ligne 134). Votre agent doit
d’abord trouver
la position la plus probable de chaque fantôme non capturé restant, puis choisir une action
qui minimise la distance entre Pacman et le fantôme le plus proche.
Pour trouver la distance du labyrinthe entre deux positions quelconques (pos1 et pos2), utilisez
self.distancer.getDistance(pos1, pos2). Pour
trouver la position du successeur d’une position après une action :
successorPosition = Actions.getSuccessor(position, action)
On vous fournit les livingGhostPositionDistributions, une liste
d’objets DiscreteDistribution représentant les
distributions
de croyance de position pour chacun des fantômes qui ne sont pas encore capturés.
Pour tester votre code :
python autograder.py -q q4
Inférence approximative
Question 5 : 2 points
Pour les prochaines questions, vous allez implémenter un algorithme de filtrage de particules pour suivre un seul fantôme.
Tout d’abord, implémentez les fonctions initializeUniformly
et getBeliefDistribution dans la classe ParticleFilter du
fichier inference.py. Une particule est une
position de fantôme dans ce problème d’inférence.
Notez que, pour l’initialisation, les particules doivent être distribuées de manière égale (et non
aléatoire) sur
les positions légales afin d’assurer une priorité uniforme. Astuce: l’opérateur mod
devrait être utilisé pour
initializeUniformly afin de permettre une
sélection uniforme des positions légales.
Notez que la variable dans laquelle vous stockez vos particules doit être une
liste. La méthode getBeliefDistribution
prendra ensuite la liste de particules et pour la convertir en un objet DiscreteDistribution.
N'oubliez pas de normaliser votre distribution après l'avoir initialisée. De plus, self.particules
hérite de la méthode count(key) permettant de
compter le nombre de répétitions de l'élément
key.
Testez votre code:
python autograder.py -q q5
Question 6 : 3 points
Ensuite, nous allons implémenter la méthode observeUpdate
dans la classe ParticleFilter dans inference.py.
Cette méthode construit une distribution de poids sur self.particles où
le poids d’une particule est la probabilité de l’observation étant donné la position de Pacman et
l’emplacement de cette particule.
Ensuite, nous rééchantillonnons à partir de cette distribution pondérée pour construire notre nouvelle
liste de particules.
Vous devez à nouveau utiliser la fonction self.getObservationProb
pour
trouver la probabilité d’une observation compte tenu de la position de Pacman, de la position d’un
fantôme potentiel et de la position de la prison.
La méthode sample de la classe
DiscreteDistribution vous sera également
utile.
Pour rappel, vous pouvez obtenir la position de Pacman en utilisant gameState.getPacmanPosition(), et la
position de la prison en utilisant self.getJailPosition().
Il y a un cas spécial qu’une implémentation adéquate doit gérer. Lorsque toutes les particules reçoivent
un poids nul,
la liste des particules doit être réinitialisée en appelant initializeUniformly.
À cet effet, la méthode total de la DiscreteDistribution
peut être utile.
python autograder.py -q q6
Question 7 : 3 points
Implémentez la fonction elapseTime
dans la classe ParticleFilter
du fichier inference.py. Cette fonction doit
construire une
nouvelle liste de particules qui correspond à chaque particule existante dans self.particles en avançant d’un pas de
temps,
puis réaffecter cette nouvelle liste à self.particles. Une fois terminé, vous
devriez être en mesure de suivre les fantômes
presque aussi efficacement qu’avec l’inférence exacte.
Notez que dans cette question, nous testerons à la fois la fonction elapseTime en isolation, ainsi que
l’implémentation
complète du filtre à particules combinant elapseTime et observe.
Comme dans la méthode elapseTime de la classe
ExactInference, vous devez utiliser :
newPosDist = self.getPositionDistribution(gameState, oldPos)
Cette ligne de code permet d’obtenir la distribution sur les nouvelles positions du fantôme, compte tenu
de sa position précédente (oldPos). La méthode
d’échantillonnage d'exemples (sample) de la classe DiscreteDistribution
sera également utile.
python autograder.py -q q7
Filtre de particules joints
Question 8 : 1 point
Jusqu’à présent, nous avons suivi chaque fantôme indépendamment, ce qui fonctionne bien pour le RandomGhost par défaut ou
le DirectionalGhost . Cependant, DispersingGhost choisit des actions qui
évitent les autres fantômes.
Puisque les modèles de transition des fantômes ne sont plus indépendants, tous les fantômes doivent être
suivis conjointement dans un réseau de Bayes dynamique !
Le réseau de Bayes a la structure suivante, où les variables cachées \(G\) représentent les positions des fantômes et les variables d’émission \(E\) sont les distances bruitées à chaque fantôme. Cette structure peut être étendue à d’autres fantômes, mais seuls deux (\(a\) et \(b\)) sont présentés ci-dessous.
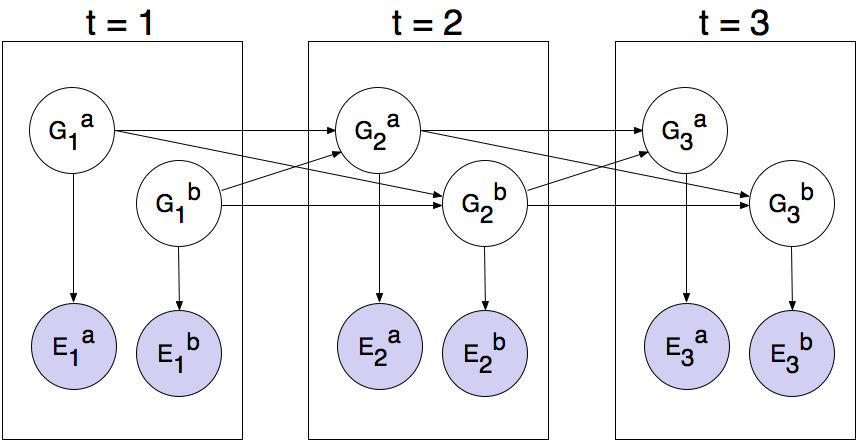
Vous allez maintenant implémenter un filtre de particules qui suit plusieurs fantômes simultanément. Chaque particule représentera un tuple de positions de fantômes qui est un échantillon de l’endroit où se trouvent tous les fantômes à l’heure actuelle. Le code est déjà configuré pour extraire les distributions marginales de chaque fantôme à partir de l’algorithme d’inférence conjointe que vous allez créer, afin de pouvoir afficher des nuages de croyances sur les fantômes individuels.
Complétez la méthode initializeUniformly dans
JointParticleFilter
du fichier inference.py. Le package de la
librairie standard
Python itertools peut vous êtres utile. Plus
précisément, consultez
itertools.product pour obtenir une
implémentation du produit cartésien.
Cependant, notez que les permutations ne sont pas retournées dans un ordre aléatoire.
Par conséquent, vous devez ensuite mélanger la liste des permutations afin d’assurer un placement
uniforme des particules
sur la carte de jeu. Après le mélange, vous pouvez utiliser l’opérateur mod pour indexer la liste des
permutations et
ajouter des particules à self.particles.
Pour clarifier, nous n’avons pas eu besoin de mélanger dans initializeUniformly de q5 parce que q8,
contrairement à q5,
a quelques tests où self.numParticles est
inférieur au nombre total de permutations, donc nous devons mélanger la liste
pour s’assurer que les premiers éléments self.numParticles
dans votre liste de permutations sont répartis uniformément
sur l’ensemble du tableau.
Comme précédemment, utilisez self.legalPositions pour obtenir une liste des
positions qu’un fantôme peut occuper et la variable dans laquelle vous stockez vos particules doit être
une liste.
python autograder.py -q q8
Question 9 : 3 points
Dans cette question, vous allez compléter la méthode observeUpdate
dans la classe JointParticleFilter de inference.py.
Votre implémentation devrait être similaire à celle de ParticleFilter, mais appliquée à plusieurs
fantômes.
Une implémentation correcte pondérera et rééchantillonnera la liste entière des particules en fonction
de l’observation de toutes les distances vers les fantômes.
Pour boucler sur tous les fantômes, utilisez :
for i in range(self.numGhosts):
...
Vous pouvez toujours obtenir la position de Pacman en utilisant gameState.getPacmanPosition(), mais pour obtenir
la position
de la prison d’un fantôme, utilisez self.getJailPosition(i),
puisqu’il y a maintenant plusieurs fantômes ayant chacun leur propre
position de prison.
Votre implémentation doit également gérer le cas particulier où toutes les particules reçoivent un poids
nul. Dans ce cas,
self.particles doit être recréé à partir de la
distribution antérieure en appelant initializeUniformly.
Comme dans la méthode de mise à jour de la classe ParticleFilter,
vous devez à nouveau utiliser la fonction self.getObservationProb
pour trouver la probabilité d’une observation étant donné la position de Pacman, une position
potentielle de fantôme et la
position de la prison. La méthode sample de la classe DiscreteDistribution
vous sera de nouveau utile.
python autograder.py -q q9
Question 10 : 2 points
Complétez la méthode elapseTime dans JointParticleFilter dans inference.py pour rééchantillonner correctement
chaque particule pour
le réseau Bayesien. En particulier, chaque fantôme doit trouver une nouvelle position conditionnée par
les positions de tous les fantômes
au pas de temps précédent.
Comme dans la dernière question, vous pouvez boucler sur les fantômes en utilisant :
for i in range(self.numGhosts):
...
Ensuite, en supposant que i se réfère à
l’indice du fantôme, pour obtenir les distributions sur les nouvelles positions pour
ce seul fantôme, étant donné la liste (prevGhostPositions)
des positions précédentes de tous les fantômes, utilisez :
newPosDist = self.getPositionDistribution(gameState, prevGhostPositions, i, self.ghostAgents[i])
Testez avec cette commande:
python autograder.py -q q10
Classifieur bayésien naïf
Question 11 : 4 points
Dans cette question vous devez implémenter un classifieur bayésien naïf multinomial pour identifier la langue d’un texte quelconque. Étant donné une matrice \(T\) avec \(n\) lignes et \(d\) colonnes où \(n\) et \(d\) représentent respectivement le nombre de documents du corpus et le nombre de mots (tokens) distincts, votre classifieur doit identifier la langue \(lang \in \{\mathrm{anglais}, \mathrm{espagnol}, \mathrm{français}, \mathrm{portugais}\}\) d'un document \(t_i \in T\), \(i = 1 \ldots n\). Chaque \(t_i\) est un vecteur \( (\mathrm{freq}(w_{i1}), \mathrm{freq}(w_{i2}), …, \mathrm{freq}(w_{id}) ) \) où \(w_{ij}\) et \(\mathrm{freq}(w_{ij})\) dénotent respectivement le mot \(j, j = 1 \ldots d\) et sa fréquence dans le document \(t_i\). Voici un exemple de la représentation des données:
Exemple :
| bonjour | hi | hello | comment | man | classe | surprise | langue | |
| T1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | french |
| T2 | 0 | 3 | 0 | 0 | 1 | 0 | 0 | english |
| T3 | 1 | 0 | 0 | 0 | 0 | 1 | 4 | french |
Dans cet exemple, le document T3 contient une fois le mot "bonjour", et quatre fois le terme "surprise".
Vous implémentez d'abord la fonction get_posterior(X) qui calcule les probabilités a
posteriori des langues étant
donné un texte. En d’autre termes,
vous devez calculer
\( \begin{align*} P(lang \mid w_1, \dots, w_d) &= P(lang) \prod_{i=1}^{d} P(w_i \mid lang)^{\mathrm{freq}(w_i)} \\ &= log\Big(P(lang)\Big) + \sum_{i=1}^d log\Big(P(w_i \mid lang)\Big) \cdot \mathrm{freq}(w_i) \end{align*} \)
où \(log(\cdot)\) représente le logarithme naturel. Pour cette implémentation,
on vous fournit les probabilités a priori \(P(lang)\) via le tableau self.prior de taille n_langues et les
probabilités des mots étant donné une langue \(P(wi\mid lang)\) sont dans la matrice self.likelihood de taille n_langues x d.
Finalement, implémentez la fonction predict(X)
qui prédit la langue de chaque
document présent dans l'entrée X. Le code
fourni convertit déjà les langues en
nombre naturel (par exemple, "français" peut être identifié par "1"). Vous devez donc simplement
retourner un vecteur de dimension équivalente
au nombre de lignes de la matrice X où chaque
élément représente le code de la langue
prédite.
Astuce: rappelez-vous de la méthode argmax de Numpy dans le TP1
et de son argument axis.
Utilisez la commande suivante pour tester votre code:
python NaiveBayesClassifier.py
Prenez une capture d'écran de la matrice de confusion et interprétez les performances de votre classifieur.(1 point)
Une bonne implementation devrait passer le test ci-après:
python NaiveBayesClassifierTest.py
| Membre 1 | Membre 2 |
|---|---|
| Duchesneau, Paul | Girard Hivon, Maxime |
| Desfossés, Alexandre | Ménard Tétreault, Yuhan |
| Krid, Ahmed Bahaedine | Breton Corona, Eduardo Yvan |
| Tientcheu Tchako, David Jeeson | Gendreau, Tommy |
| Pion, Raphaël | Yahya, Mohamed |
| Carignan, Benjamin | Bourgeois, Thomas |
| Grenier, Philippe-Olivier | Proulx, Hugo |
| Philion, Guillaume | Lavallée, Louis |
| Dia, Adam | Lamothe-Morin, Zoé |
| Bellavance, Nicolas | Crozet, Thomas |
| Pépin, Pierre-Luc | Tétreault, Etienne |
| Boutin, Karl | Turcotte, Raphaël |
| Mailhot, Christophe | Allard, Cloé |
| Bergeron, Marc-Olivier | Boulanger, Bastien |
| Lessard, Nathan | Gauthier, Carl |
| Giasson, Frédéric | Charbonneau, Victor |