TP 1 : Perceptron
La composition des équipes est fournie avec cet énoncé et est obligatoire. [cliquez ici pour voir]
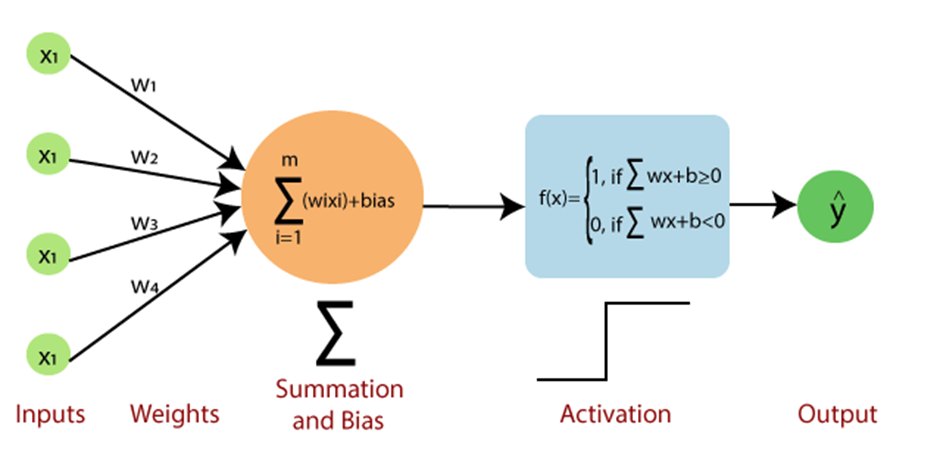
Introduction
Dans ce travail pratique, vous êtes invité à implémenter un modèle de classification linéaire appelé le perceptron, et le tester sur des données. L'ensemble de données \(\mathbb{D}=\left\{(x_i, y_i) : i =0,...,N; x_i \in \mathbb{R}^D, yi \in \{0,...,C\}\right\}\) est fourni sous forme d’une matrice \(X \in \mathbb{R}^{N \times D}\) et \(Y \in \mathbb{\{0, 1\}}^{N}\), avec \(N\) le nombre d'exemples, et \(D\), la dimension de chaque exemple.
Notons \({y_i}\), et \(\hat{y_i}\), la classe réelle (ground truth) et la classe prédicte de la donnée \(x_i \in X\), respectivement.
Nous avons vu que \(\hat{y} = h_w(x_i)=Threshold(\mathbf{w} \cdot \mathbf{x^T} + b)\). Voir ift615-04-Classification lineaire avec le perceptron
Voici l'algorithme de la règle de perceptron:

Le code pour ce projet est disponibles ici : fichier compressé.
Fichiers à modifier et soumettre : vous devez remplir les sections manquantes du fichier
models.py. Il ne faut pas modifier les autres fichiers.
Évaluation : l'auto-correcteur s'assure du bon fonctionnement de votre code.
Ne changez aucun nom de fonction ou nom de classe dans le code, sans quoi l'auto-correcteur ne
fonctionnera
pas.
L'auto-correcteur ne détermine pas entièrement votre résultat final. La qualité de votre implémentation
- et
non les résultats obtenus par l'auto-correcteur - déterminent votre résultat final.
Pour évaluer votre code, vous pouvez utiliser l’auto-correcteur automatique à l’aide de la commande:
python autograder.pypython autograder.py -q q1python autograder.py --no-graphicsUtilisation des données : une partie des notes obtenues dépend de la performance de votre modèle sur l'ensemble de test. La base de code n'offre aucun API permettant d'accéder à cet ensemble directement. Par conséquent, toute tentative de modification des données de test sera considérée comme de la tricherie et sera sévèrement pénalisée en conséquence.
Aide : N'hésitez pas à contacter les assistants à l'enseignement pour ce cours afin de vous aider dans le travail.
Installation
Pour ce projet, vous devez installer des librairies suivantes :
- numpy
- scikit-learn
- matplotlib, une librairie de visualisation - installation
Note : Vous devez avant tout créer un environement virtuel de la manière suivante:
- Avec pip :
python -m venv envpip install matplotlib scikit-learn numpy - Avec conda :
conda create --name ift615 python=3.9conda activate ift615conda install scikit-learn matplotlib
Voici les liens ressources pour vous familiariser avec conda et numpy.
Vous pouvez vérifier que votre environment et les dépendances sont bien installés en utilisant la commande ci-dessous:
python autograder.py --check -dependencies
Question 1 : Perceptron binaire (24 pts)
a) Mise à jour manuelle du perceptron (6 pts)
À partir du tableau ci-dessous, exécutez une itération complète de l’algorithme du perceptron avec un taux d’apprentissage α = 0.1. Donnez la valeur des poids \(\mathbf{w}\) et du biais b après chaque donnée parcourue. Prenez en photo vos calculs et incluez les dans un fichier nommétp1-calculs.png.
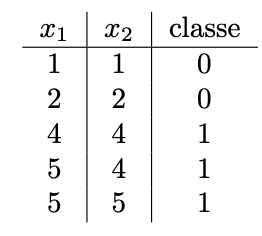
b) Visualisation de la barrière de décision (5 pts)
Il est souvent utile de visualiser la barrière de décision d’un modèle d’apprentissage automatique. Cela nous permet notamment d’évaluer visuellement la capacité de généralisation et la qualité de notre modèle. Supposez que les paramètres optimaux du perceptron sont \(\mathbf{w}^∗ = (0.0001~~~ 0.0001)\) et \(b^∗ = −0.0006\). Dessinez le nuage de points avec les données du tableau ci-dessus et tracez la droite représentant la barrière de décision. Dessinez le graphique sur une feuille et prenez-la en photo ou utilisez un logiciel pour produire la droite et le nuage de points. Nommez le fichier q1b.png et ajoutez le à votre soumission. Prenez en photo vos calculs et incluez les dans le fichiertp1-calculs.png. Voici un exemple de solution avec des données
différentes :
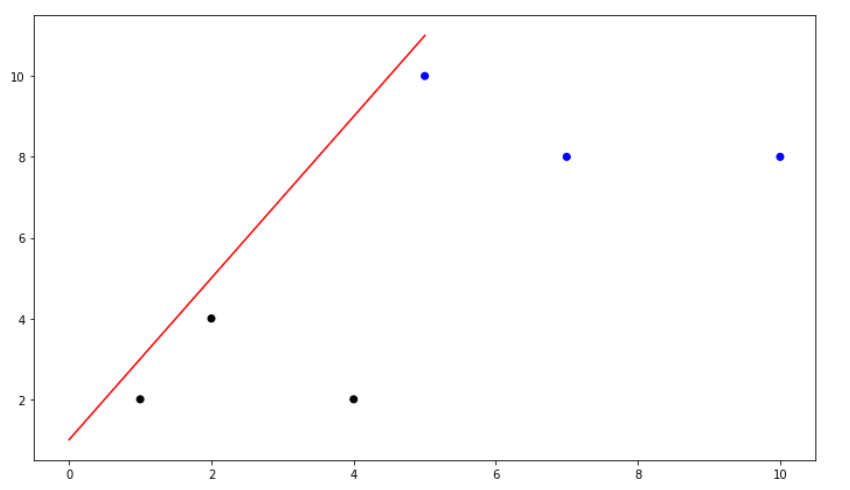
- Définissez l’équation de la droite et isolez en fonction de \(x1\) et \(x2\). Déterminer l’ordonnée et l’abscisse à l’origine et finalement trouver la pente de la droite.
- Vous pouvez utiliser les logiciels Geogebra, Desmos ou encore la librairie Matplotlib afin de produire le nuage de points.
c) Implémentation informatique du perceptron binaire (13 pts)
Maintenant que vous maîtrisez la procédure de mise à jour du perceptron, vous pouvez implémenter
l’algorithme complet. Un squelette de code est déjà fourni. Vous devez le compléter.
Complétez les fonctions init_params, threshold, predict, fit
de la classe BinaryPerceptron à partir du fichier models.py.
Numpy profite d’accélération matérielle afin de rendre les
calculs mathématiques très rapides. Pour cette raison, vous êtes encouragé à utiliser son API et éviter
les boucles et itérations qui ralentissent significativement l’exécution de votre code. Un excellent
tutoriel sur Numpy est offert sur ce lien.
Barème
| Critère | Points |
| fit | 5 |
| predict | 3 |
| init_params | 2 |
| threshold | 1 |
Pas de boucles for inutiles (code vectorisé) |
1 |
| qualité / lisibilité du code | 1 |
| Total | 13 |
python autograder.py -q q1Question 2 : Perceptron multi-classe (13pts)
Nous avons traité le cas du perceptron binaire. Nous pouvons maintenant généraliser son application
à plusieurs classes. Dans cet exercice, nous entraînons un perceptron à reconnaître des chiffres
manuscrits. Pour ce faire, nous utilisons la célèbre base de données NIST (à ne pas confondre avec
MNIST) qui contient 1797 exemples de chiffres manuscrits en 16 tonalités de gris. Chaque image est
de taille (8, 8) et par conséquent nos données sont de la forme \(X \in \mathbb{R}^{1797 \times
64}\).
Le perceptron multiclasse se comporte de manière similaire au perceptron binaire, mais utilise
plutôt un vecteur de poids par classe, un vecteur pour le biais et un critère de décision différent.
Formellement, soit \(\mathbf{C}\) le nombre de classes distinctes à prédire, \(\mathbf{W} \in
\mathbb{R}^{C \times D}\) la matrice des poids et \(\mathbf{b} \in \mathbb{R}^{C}\) le vecteur de
biais. L’objectif du percetron multiclasse est de trouver la matrice \(\mathbf{W}^*\) et le vecteur
\(\mathbf{b}^*\) qui minimisent les erreurs de classification.
Dans ce cas, la logique du score demeure la même, mais on effectue maintenant un produit matriciel
plutôt qu’un produit vectoriel. Pour chaque donnée \(x_i\), son score est un vecteur de taille
\(\mathbf{C}\). La classe prédite sera celle avec le plus grand score.
\(h_w(\mathbf{X}) = argmax \left\{\mathbf{X}\mathbf{W}^T + \mathbf{b}\right\}\).
Lors d’une itération sur une donnée \(\mathbf{x_i} \in \mathbf{X}\), on compare son étiquette \(y_i\) avec sa prédiction \(\hat{y}_i\). Si \(y_i = \hat{y}_i\), on ne fait rien. Sinon, on doit mettre à jour les poids associés au neurone \(y_i \) et \(\hat{y}_i\) comme suit, afin d’éviter cette erreur de classification.
\(\mathbf{b}[{y}]= \mathbf{b}[{y}] + \alpha\)
\(\mathbf{W}[{\hat{y}},:]=\mathbf{W}[{\hat{y}},:] - \alpha \mathbf{x_i}\)
\(\mathbf{b}[{\hat{y}}]=\mathbf{b}[{\hat{y}}] - \alpha\)
Dans le fichier models.py, implémentez les méthodes init_params, predict
et fit de la classe MulticlassPerceptron.
Barème
| Critère | Points |
| fit | 5 |
| predict | 5 |
| init_params | 2 |
Pas de boucles for inutiles (code vectorisé) |
3 |
| qualité / lisibilité du code | 1 |
| Total | 16 |
python autograder.py -q q2Les équipes:
| Membre 1 | Membre 2 |
|---|---|
| Proulx, Hugo | Turcotte, Raphaël |
| Pion, Raphaël | Charbonneau, Victor |
| Pépin, Pierre-Luc | Bourgeois, Thomas |
| Bellavance, Nicolas | Desfossés, Alexandre |
| Grenier, Philippe-Olivier | Thiam, Fatou |
| Tétreault, Etienne | Boubacar Boureima, Mohamed |
| Rouabah, Lokman | Boulanger, Bastien |
| Lavallée, Louis | Blanchy, Timothée |
| Yahya, Mohamed | Breton Corona, Eduardo Yvan |
| Duchesneau, Paul | Tientcheu Tchako, David Jeeson |
| Lessard, Nathan | Crozet, Thomas |
| Allard, Cloé | Gendreau, Tommy |
| Lamothe-Morin, Zoé | Bergeron, Marc-Olivier |
| Boutin, Karl | Giasson, Frédéric |
| Girard Hivon, Maxime | Krid, Ahmed Bahaedine |
| Moulay Abdallah, Mustapha | Gauthier, Carl |
| Philion, Guillaume | Mailhot, Christophe |
| Carignan, Benjamin | Ménard Tétreault, Yuhan |